

 در این بخش آموزش سئو و مفاهیم اولیه و پیشرفته ی سئو را ارائه خواهیم داد. آموزش هایی که ما در نظر گرفتیم هم شامل کسانی که مبتدی و اول راه هستند و هم مناسب افراد سئوکار حرفه ای می باشد.
در این بخش آموزش سئو و مفاهیم اولیه و پیشرفته ی سئو را ارائه خواهیم داد. آموزش هایی که ما در نظر گرفتیم هم شامل کسانی که مبتدی و اول راه هستند و هم مناسب افراد سئوکار حرفه ای می باشد.
SEO مخفف عبارت Search Engine Optimization است. به این معنی که تکنیک هایی را برای بهینه سازی وب سایت ها ارائه می دهد تا بتوانیم رتبه خوبی در موتورهای جستجو بگیریم.
این آموزش های ما شامل تمامی موضوعات بهینه سازی موتورهای جستجو مانند تکنیک های سئو کلاه سیاه و سفید، نحوهی کار موتور جستجو، نحوه ی انجام تحقیقات بازار سئو، تحقیق کلمات کلیدی، تکنیک های بهینه سازی On Page، تکنیک های بهینه سازی Off Page، بهینه سازی شبکه های اجتماعی، ابزارهای سئو و غیره می باشد.
تعریف سئو
SEO مخفف عبارت Search Engine Optimization است. در واقع سئو شامل فرآیندی است که برای بهینه سازی سایت برای موتورهای جستجو طراحی شده است. زمانی که فردی در باکس جستجوی گوگل عبارت یا کلمه ی مورد نظر خود را جستجو میکند سئو کاری میکند که وب سایت شما در رتبه های بالاتر و صفحات اول نتایج گوگل دیده شوید. در نتیجه ما در وب سایت خود باید فعل و انفعالاتی انجام دهیم و درصدد افزایش کمیت و کیفیت ترافیک وب سایت خود باشیم و این امر نیز تنها با دستیابی به رتبه های برتر گوگل امکانپذیر است. برای اینکه پروسه انجام سئو را بهتر کنید، تصویر زیر را نگاه کنید.
سئو چیست؟
در واقع وقتی توسط کاربران جستجویی صورت میگیرد نتایج این جستجو بصورت یک لیست مرتب شده ارائه میشود و سایتهایی که در رتبه های بالاتر مانند لینک یک دو و سه این نتایج هستند توسط کاربران بیشتر کلیک میخورند و بیشتر ورودی میگیرند و ترافیک بیشتری خواهند داشت. برای مثال میتوان گفت که، برای یک عبارت جستجو شده، نتیجه ای که در رتبه اول قرار دارد، حدود 40 تا 60 درصد از کل ترافیک ایجاد شده برای آن عبارت یا کلمه را دریافت می کند. تنها 2 تا 3 درصد کاربران امکان دارد که به صفحه ی دوم نتایج جستجو مراجعه کنند. برای آموزش کامل مقاله سئو چیست را در سئو طلوع مطالعه کنید.
بهینه سازی موتور جستجو چگونه عمل می کنند؟
وقتی جستجویی در موتورهای جستجو صورت میگیرد برای اینکه تعیین شود چه کسی و در چه کلمه و عبارتی در رتبه های بالاتر و صفحات اول نتایج قرار بگیرند، گوگل با استفاده از الگوریتمها و قوانین خاصی که دارد بررسی و آنالیز میکند و سپس جایگاه هر سایت و صفحه را مشخص مینماید. این الگوریتم ها رتبه بندی SERP ها را با توجه به فاکتورهای مختلف رتبه بندی و تعیین می کنند. باید دقت داشته باشید که معیارهای خاصی برای ارزیابی کیفیت یک صفحه وجود دارد و بر این اساس است که تصمیم گیری در رتبه بندی صورت میگیرد.
معیارهای اصلی مورد استفاده توسط موتورهای جستجو:
لینک ها: لینک های سایت یا همان بک لینک ها. این لینک ها به تعیین رتبه سایت در SERP کمک می کنند. یک لینک به عنوان یک رای برای تایید کیفیت وب سایت ها در نظر گرفته می شود، زیرا صاحب وب سایت به سایتی که کیفیت پایینی دارد لینک نمی دهد.
محتوا: کیفیت محتوا یک پارامتر حیاتی در تعیین رتبه سایت است. محتوا باید یونیک باشد و همچنین مرتبط با عبارت جستجو شده باشد.
ساختار صفحه: همانطور که میدانید صفحات وب سایت به زبان HTML نوشته شده اند. کد نویسی html یک صفحه توسط موتورهای جستجو برای ارزیابی یک صفحه مورد بررسی قرار میگیرند. بنابراین کلمات کلیدی مهم را در عنوان، URL و سایر متا تگ ها قرار دهید و همچنین مطمئن شوید که سایت قابل خزیدن است.
انواع سئو
در بخش قبل گفتیم که خدمات سئو فرآیند بهینه سازی یک وب سایت (ساده سازی وب سایت برای موتورهای جستجو و کاربران) برای افزایش ترافیک ارگانیک است. موتورهای جستجو مانند گوگل دستورالعمل هایی دارند که باید هنگام بهینه سازی سایت از آنها پیروی کنیم. اگر سئو طبق دستورالعمل انجام شود و بهینه گردد به آن سئو کلاه سفید میگوییم و اگر بدون رعایت دستورالعمل ها انجام شود به آن سئو کلاه سیاه می گوییم. بنابراین، دو نوع سئو وجود دارد:
سئو کلاه سفید
به تکنیک های SEO که مطابق با دستورالعمل های SEO توسط موتورهای جستجو انجام میگردد، اشاره دارد. به این معنی که از تکنیک های تایید شده بهینه سازی موتور جستجو برای بهبود رتبه سایت در صفحات نتایج موتور جستجو یا همان SERPها استفاده می کند.
برعکس سئو کلاه سیاه، در این روش بیشتر سئوکاران بفکر مخاطبان و کاربران خود هستند و سایت را برای آنها بهینه میکنند بجای اینکه برای موتور جستجو بهینه کنند. افرادی که به دنبال سرمایه گذاری بلند مدت برای وب سایت خود هستند از تکنیک های سئو کلاه سفید استفاده میکنند. نمونه هایی از سئوی کلاه سفید شامل ایجاد محتوای با کیفیت، لینک سازی داخلی، ساخت لینک، بهینه سازی سایت، بازاریابی شبکه های اجتماعی، تبلیغات گوگل و غیره است.
سئو کلاه سیاه
به تکنیک های سئویی اشاره دارد که مطابق با دستورالعمل های SEO تنظیم شده توسط موتورهای جستجو نیست. این تکنیک ها از نقاط ضعف موتورهای جستجو برای کسب رتبه های بالاتر برای وب سایت ها در صفحات نتایج موتور جستجو SERPها استفاده می کنند.
در این روش بیشتر بر روی موتورهای جستجو تمرکز می کنند و کاربران برای آنها در اولویت نمیباشند. افرادی که بهجای سرمایهگذاری بلندمدت به دنبال بازگشت مالی سریع در وبسایت خود هستند، از تکنیکهای سئو کلاه سیاه استفاده میکنند.
گاهی اوقات ممکن است در مدت زمان کوتاهی به نتایج دلخواهتان برسید، اما فقط برای مدت کوتاهی است، و به مرور زمان نتیجه برعکس خواهد شد، به عنوان مثال، ممکن است رتبه شما کاهش پیدا کند و شما را در لیست سیاه موتورهای جستجو قرار دهد. نمونه هایی از سئو کلاه سیاه عبارتند از استفاده ی بیش از حد کلمات کلیدی، محتوای تکراری، پنهان کردن، پنهان کردن محتوا، محتوای ضعیف، صفحات درگاه، لینک های scheme و غیره.
تفاوت سئو کلاه سفید با سئو کلاه سیاه
سئو کلاه سفید

- تکنیک هایی که با دستورالعمل های موتورهای جستجو مطابقت دارند برای بهبود رتبه بندی موتورهای جستجو استفاده می شوند.
- لازم نیست نگران جریمه شدن یا حذف ایندکس سایت خود باشید.
- تمرکز بر ارائهی محتوای با کیفیت و مرتبط به کاربران.
- مناسب برای افرادی که به دنبال سرمایه گذاری بلند مدت هستند.
- بیشتر بر استفادهی بهینه از کلمات کلیدی در عنوان، متاتگ ها و بدنهی محتوا تمرکز دارد.
سئو کلاه سیاه

- در سئو کلاه سیاه از تکنیک هایی استفاده میشود که توسط موتورهای جستجو تایید نشده اند.
- ممکن است سایت شما توسط موتورهای جستجو جریمه شود، و دیگر سایت شما ایندکس نشود یا پنالتی شود.
- به کیفیت محتوا اهمیت نمیدهد.
- افرادی که به دنبال بازگشت سریع سرمایه هستند سئو کلاه سیاه را ترجیح می دهند.
- تراکم کلمات کلیدی برای دستیابی به رتبهی بالاتر در موتورهای جستجو افزایش می یابد.
سئو کلاه سفید
در این بخش ما لیستی از 6 تکنیک محبوب سئو کلاه سفید را برای شما ذکر خواهیم کرد:
- محتوای جذاب و باکیفیت
- استفاده صحیح از عنوان، کلمات کلیدی و متاتگ ها
- سهولت در هدایت به صفحات دیگر
- عملکرد سایت
- لینک های ورودی با کیفیت
- سازگاری با موبایل
1) محتوای خوب
یک محتوای یونیک و روان باعث می شود وب سایت شما برای موتورهای جستجو و بازدیدکنندگان قابل اعتمادتر و ارزشمندتر به نظر برسد و در واقع از این طریق اعتماد سازی شکل خواهد گرفت. و در اینصورت وب سایت شما برای موتورهای جستجو بهینه خواهد شد، که به شما کمک می کند رتبه بالاتری در لیست نتایج موتورهای جستجو کسب کنید زیرا موتورهای جستجو مناسب ترین وب سایت را برای جستجوی کاربران نهایی ارائه می دهند.
2) استفاده صحیح از عنوان، کلمات کلیدی و متاتگ ها
اطلاعات موجود در کد HTML به عنوان متا دیتا شناخته می شود. و اطلاعات مربوط به سایت را برای طبقه بندی و ایندکس کردن در اختیار کراولرها قرار می دهد. بنابراین، عنوان، کلمه کلیدی و متاتگ مناسب باید در متا دیتا گنجانده شود.
3) سهولت در هدایت به صفحات دیگر
موتورهای جستجو در حین ارزیابی اینکه آیا این سایت سودمند هست یا خیر، سهولت پیمایش در صفحات را نیز در نظر می گیرند، بنابراین از لینکهای نامربوط خودداری کنید و از لینکهایی استفاده کنید که قابل تشخیص باشند. این نه تنها برای کاربران بلکه برای خزنده هایی که سایت ها را ایندکس می کنند نیز بسیار مهم است.
4) عملکرد سایت
عملکرد سایت و صفحه یکی دیگر از عواملی است که موتورهای جستجو برای ارزیابی سایت ها در نظر می گیرند. سایت های در دسترس یا صفحات در دسترس نمی توانند توسط خزنده های موتورهای جستجو ایندکس شوند. اگر سایت شما به مدت یک هفته یا حتی یک روز از دسترس کاربران خارج شود بر ترافیک سایت تأثیر منفی خواهد گذاشت. بنابراین، از اینکه سایت شما سریع لود می شود و همیشه در دسترس است مطمئن شوید.
5) لینک های ورودی باکیفیت
سایت باید دارای لینک های ورودی باکیفیت باشد زیرا موتورهای جستجو به طور مرتب بک لینک ها را برای ارتباط آنها ارزیابی می کنند. اگر مشخص شود که سایتی دارای بک لینک های نامربوط است، توسط موتور جستجو پنالتی یا جریمه می شود، به عنوان مثال، یک وب سایت در مورد کشاورزی در ایران که حاوی تعدادی لینک از وب سایت های اروپایی در مورد فناوری است توسط موتورهای جستجو شناسایی و جریمه می شود. برای خرید بک لینک معتبر و مطابق با الگوریتم های گوگل، به صفحه خرید بک لینک سئو طلوع مراجعه کنید.
6) سازگاری با موبایل
اموزه موبایل فرندلی بودن سایت به یک عامل مهم در سئو تبدیل شده است زیرا گوگل از سال 2016 روی نتایج موبایل تاکید بسیاری کرد. دلیل این امر این است که کاربران بسیار زیادی از تلفنهای هوشمند استفاده میکنند و محتوا را توسط تلفن همراه خود چک میکنند و جستجو مینمایند. بنابراین، مطمئن شوید که یک سایت سازگار با موبایل دارید.
سئو کلاه سیاه
در این بخش لیستی از 10 تکنیک برتر سئو کلاه سیاه را برای شما آورده ایم:
تکنیک های سئو کلاه سیاه سئو
- استفاده ی بیش از حد از کلمات کلیدی
- Cloaking
- متن پنهان
- صفحات درگاه
- بازنویسی مقاله
- محتوای تکراری
- تعویض صفحه
- لینک های مزرعه
- دزدیدن URL
- استفاده نادرست از اسنیپت ها
1) پر کردن کلمات کلیدی و استفاده ی بیش از حد از آنها
موتور جستجو کلمات کلیدی و عبارات کلیدی را در صفحات وب تجزیه و تحلیل می کند تا وب سایت ها را ایندکس کند. برای بهره برداری از این ویژگی موتور جستجو، برخی از متخصصان سئو، تراکم کلمات کلیدی را افزایش می دهند تا رتبه بالاتری کسب کنند، که یک تکنیک سئو کلاه سیاه در نظر گرفته می شود. چگالی کلمه کلیدی بین دو تا چهار درصد، بهینه در نظر گرفته می شود، افزایش تراکم کلمه کلیدی بیش از آن کاربران سایت و خوانندگان شما را آزار می دهد و بر رتبه شما تأثیر می گذارد.
2) Cloaking
این در واقع به کدنویسی صفحات وب به گونه ای اشاره دارد که موتورهای جستجو یک مجموعه از محتوا را می بینند و بازدیدکنندگان یک محتوای دیگر را می بینند، به عنوان مثال، کاربر وقتی عبارتی مانند “قیمت طلا” را جستجو میکند و نتیجه جستجو “قیمت فعلی طلا” را کلیک می کند و تمایل دارد که قیمت فعلی طلا را ببیند. اما یک سایت مسافرتی و گردشگری برای او باز میشود، در واقع این روش مطابق با دستورالعمل های موتورهای جستجو نیست زیرا که می گویند برای کاربران محتوا ایجاد کنید نه برای موتورهای جستجو.
3) متن پنهان
متنی که موتورهای جستجو می توانند مشاهده کنند اما خوانندگان نمی توانند آن را مشاهده کنند به عنوان متن پنهان شناخته می شود. این تکنیک برای ترکیب کلمات کلیدی نامربوط و پنهان کردن متن یا لینکها برای افزایش تراکم کلمات کلیدی یا بهبود ساختار لینک داخلی استفاده می شود. برخی از راههای پنهان کردن متن عبارتند از: اندازه فونت متن را صفر میکنند، استفاده از CSS برای تنظیم متن خارج از صفحه، متن را سفید در تنظیم میکنند با پسزمینهی سفید و غیره.
4) صفحات درگاه
صفحات بد نوشته شده که از نظر کلمات کلیدی غنی هستند اما حاوی اطلاعات مرتبط نیستند و بر لینکهایی برای هدایت کاربران به یک صفحه غیرمرتبط تمرکز می کنند، صفحات درگاه نامیده می شوند. این صفحات توسط متخصصان سئو کلاه سیاه برای انتقال ترافیک کاربران به سایت های غیر مرتبط استفاده می شود.
5) بازنویسی مقاله
این کار شامل بازنویسی یک مقالهی واحد برای تولید نسخه های مختلف آن به گونه ای است که هر نسخه مانند یک مقاله جدید به نظر برسد. محتوای این گونه مقالات تکراری، ضعیف نوشته شده و برای بازدیدکنندگان ارزش کمی دارد. در این تکنیک، چنین مقالاتی به طور مرتب انتشار داده می شوند تا وانمود کنند که مقالات تازه را ایجاد میکنند.
6) محتوای تکراری
محتوای کپی شده از یک وب سایت برای انتشار در وب سایت دیگر به عنوان محتوای اصلی، به عنوان محتوای تکراری شناخته می شود. این تکنیک کلاه سیاه به عنوان سرقت ادبی نیز شناخته می شود.
7) تعویض صفحه (Bait-and-Switch)
در این تکنیک، ابتدا صفحه وب را در فهرست های موتور جستجو ایندکس و رتبه بندی می کنید، سپس محتوای صفحه را به طور کامل تغییر می دهید. در این حالت، وقتی کاربر روی یک نتیجه در SERP کلیک می کند، به صفحه دیگری هدایت داده می شود.
8) مزارع لینک
مزرعه لینک یک وب سایت یا مجموعه ای از وب سایت ها است که هدف آن افزایش محبوبیت لینک یک سایت از طریق افزایش تعداد لینک های ورودی است. سئو کلاه سیاه در نظر گرفته می شود زیرا لینک سایت های مزارع دارای کیفیت پایین و محتوای نامربوط است.
9) دزدیدن URL (Typosquatting)
در اینجا، نام دامنه ای که نسخه غلط املایی یک وب سایت محبوب یا سایت رقیب است، در تلاش برای گمراه کردن بازدیدکنندگان ثبت می شود. به عنوان مثال، dijikala.com ممکن است کاربرانی را که می خواهند از digikala.com بازدید کنند گمراه کند.
10) استفاده نادرست از اسنیپت ها
در این تکنیک سئو کلاه سیاه، قطعاتی که مربوط به سایت یا صفحه شما نیستند برای هدایت ترافیک به یک وب سایت استفاده می شود. به عنوان مثال، استفاده از یک review snippet حتی زمانی که صفحه شما single review دارد.
موتور جستجو چگونه کار می کند؟

کار موتور جستجو به سه بخش تقسیم می شود، یعنی خزیدن یا کراول کردن، ایندکس کردن و بازیابی (retrieval).
خزیدن:
این اولین مرحله ای است که در آن یک موتور جستجو از خزنده های وب برای پیدا کردن صفحات وب در وب جهانی استفاده می کند. خزنده وب، برنامه ای است که توسط گوگل برای ایجاد ایندکس استفاده می شود. این برنامه در واقع برای خزیدن (Crawl) و ورود به صفحات طراحی شده است، که در آن خزنده، وب را مرور می کند و اطلاعات مربوط به صفحات وب بازدید شده توسط خود را در قالب یک ایندکس ذخیره می کند.
بنابراین، موتورهای جستجو دارای کراولرها یا اسپایدرها برای انجام خزش هستند و وظیفه خزنده بازدید از یک صفحه وب، خواندن آن و دنبال کردن لینک های سایر صفحات وب سایت است. هر بار که خزنده از یک صفحه وب بازدید می کند، صفحه را کپی می کند و URL آن را به ایندکس اضافه می کند. پس از افزودن URL، مرتباً مثلا هر یا دو ماه یکبار از سایتها بازدید میکند تا بهروزرسانی یا تغییرات را جستجو کند.
ایندکسینگ:
در این مرحله، کپیهایی از صفحات وب که توسط خزنده در حین خزیدن ایجاد شده است، به موتور جستجو بازگردانده شده و در یک مرکز داده ذخیره میشوند. با استفاده از این کپی ها، خزنده ایندکس موتور جستجو را ایجاد می کند. هر یک از صفحات وب که در لیست های موتورهای جستجو مشاهده می کنید توسط خزنده بررسی شده و به ایندکس اضافه می شوند. پس وب سایت شما باید ایندکس شود و تنها پس از آن در صفحات موتور جستجو ظاهر می شود.
می توان گفت که این ایندکس مانند یک کتاب بزرگ است که شامل یک کپی از هر صفحه وب است که توسط خزنده یافت می شود. اگر هر صفحه وب تغییر کند، خزنده ها کتاب را با محتوای جدید به روز می کند!
بنابراین، ایندکس شامل URL صفحات وب مختلف است که توسط خزنده بازدید می شود و حاوی اطلاعات جمع آوری شده توسط خزنده ها است. این اطلاعات توسط موتورهای جستجو برای ارائهی پاسخ های مرتبط به کاربران برای پرسش هایشان استفاده می شود. اگر صفحه ای به ایندکس اضافه نشود، در دسترس کاربران نخواهد بود. ایندکسینگ یک فرآیند پیوسته است. خزنده ها همواره به بازدید از وب سایت ها برای یافتن داده های جدید ادامه می دهند.
بازیابی (retrieval):
این مرحله نهایی است که در آن موتور جستجو مفیدترین و مرتبط ترین پاسخ ها را با ترتیبی خاص در پاسخ به درخواست جستجوی ارسال شده توسط کاربر ارائه می دهد.
موتورهای جستجو از الگوریتمهایی برای بهبود نتایج جستجو استفاده میکنند تا فقط اطلاعات واقعی به کاربران برسد، به عنوان مثال، PageRank یک الگوریتم محبوب است که توسط موتورهای جستجو استفاده میشود. از طریق صفحات ثبت شده در ایندکس جابجا می شود و آن صفحات وب را در صفحه اول نتایجی که فکر می کند بهترین هستند نشان می دهد.
دامنه چیست؟
نام دامنه، هویت یک یا چند آدرس IP است. به عنوان مثال، نام دامنه google.com به آدرس IP “74.125.127.147” اشاره می کند. نام دامنه به این جهت بوجود آمد که به خاطر سپردن یک نام به جای یک رشته طولانی از اعداد بسیار آسان تر است. همچنین وارد کردن یک نام دامنه در نوار جستجو آسان تر است تا یک دنباله طولانی از اعداد پشت سر هم.
بنابراین، این آدرس وب سایت شما است که افراد برای بازدید از وب سایت شما باید در نوار URL مرورگر تایپ کنند. به عبارت ساده، فرض کنید وب سایت شما یک خانه است، و نام دامنه آدرس آن است.
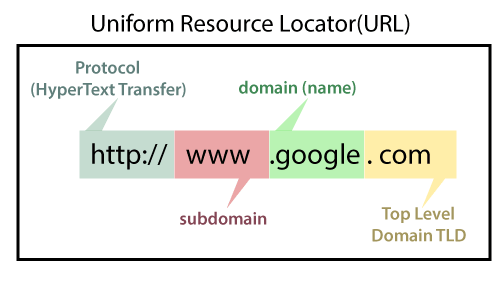
یک دامنه نمی تواند بیش از شصت و سه کاراکتر داشته باشد. به استثنای .com، .net، .org، .edu.. . حداقل طول یک دامنه یک کاراکتر به استثنای پسوندها است. همانطور که در مثال زیر و تصویر نشان داده شده است، پس از پروتکل و زیر دامنه در URL وارد می شود:
- https://www.google.com
- https: ( Protocol)
- www. (Subdomain)
- google.com (domain and domain suffix)
نحوه عملکرد نام دامنه
هنگامی که نام دامنه در مرورگر وب شما وارد می شود، درخواستی به شبکه جهانی سرورهایی ارسال می شود که سیستم نام دامنه (DNS) را تشکیل می دهند، که مانند دفترچه تلفن در فضای اینترنت است.
سپس سرور، سرورهای نام مربوط به دامنه را جستجو کرده و درخواست را به name servers ارسال می کند. نیم سرورها (name servers ) کامپیوترهای بزرگی هستند که توسط شرکت های میزبان مدیریت می شوند. شرکت میزبان درخواست را به وب سروری که سایت شما در آن ذخیره شده است ارسال می کند. وب سرور صفحه وب یا اطلاعات درخواستی را جست وجو می کند و آن را به مرورگر ارسال می کند.
سیستم نام های دامنه توسط شرکت اینترنتی برای نام ها و شماره های اختصاص داده شده (ICANN) مدیریت می شود. این یک سازمان غیرانتفاعی است که خط مشی های نام دامنه را ایجاد و اجرا می کند.
ICANN به شرکت هایی که نام های دامنه را ریجستر میکنند مجوز می دهد. همچنین به آنها اجازه می دهد تا از طرف شما تغییراتی در ثبت نام دامنه ایجاد کنند و نام دامنه را بفروشند، سوابق آنها را مدیریت کنند، تمدید کنند و به سایر ثبت کنندگان انتقال دهند.
به عنوان صاحب نام دامنه، شما باید نام دامنه خود را قبل از انقضای تاریخ اعتبار آن تمدید نمایید.
WWW چیست؟
وب جهانی که به عنوان وب نیز شناخته می شود، مجموعه ای از وب سایت ها یا صفحات وب است که در سرورهای وب ذخیره شده و از طریق اینترنت به رایانه های محلی متصل می شوند. این وب سایت ها حاوی صفحات متنی، تصاویر دیجیتال، فایل های صوتی، ویدئویی و غیره هستند. کاربران می توانند از هر نقطه ای از جهان از طریق اینترنت با استفاده از دستگاه های خود مانند رایانه، لپ تاپ، تلفن همراه و غیره به محتوای این سایت ها دسترسی داشته باشند. WWW، همراه با اینترنت، بازیابی و نمایش متن و رسانه را در دستگاه شما امکان پذیر می کند.
اجزای سازنده وب جهانی، صفحات وب هستند که به صورت HTML فرمت شده و با لینکهایی به نام “hypertext” یا hyperlinks به هم متصل می شوند و توسط HTTP قابل دسترسی هستند.
این لینک ها اتصالات الکترونیکی هستند که اطلاعات مرتبط را به هم لینک می دهند تا کاربران بتوانند به سرعت به اطلاعات مورد نظر دسترسی پیدا کنند. Hypertext (فرامتن) این مزیت را برای انتخاب یک کلمه یا عبارت از متن و در نتیجه دسترسی به صفحات دیگری که اطلاعات اضافی مربوط به آن کلمه یا عبارت را ارائه می دهند.
به هر یک صفحه وب یک آدرس آنلاین به نام Uniform Resource Locator URL داده می شود. مجموعه خاصی از صفحات وب که متعلق به یک URL خاص هستند، وب سایت نامیده می شوند، به عنوان مثال:
www.seotolu.com
www.google.com و….
بنابراین، وب جهانی مانند یک کتاب الکترونیکی عظیم است که صفحات آن در چندین سرور در سراسر جهان، وب سایت های کوچک همه صفحات وب خود را روی یک سرور ذخیره می کنند، اما وب سایت ها یا سازمان های بزرگ صفحات وب خود را بر روی سرورهای مختلف در کشورهای مختلف قرار می دهند تا هنگامی که کاربران یک کشور سایت خود را جستجو می کنند بتوانند به سرعت اطلاعات را از نزدیکترین سرور دریافت کنند. بنابراین، وب بستر ارتباطی کاربران را برای بازیابی و تبادل اطلاعات از طریق اینترنت فراهم می کند. بر خلاف کتاب خواندن که در آن از صفحه ای به صفحه دیگر به صورت متوالی جابه جا می شویم، در شبکه جهانی وب از لینکهای هایپرتکست برای بازدید از یک صفحه وب و از آن صفحه وب برای انتقال به صفحات وب دیگر پیروی می کنیم. همچنین برای دسترسی به وب، به مرورگری نیاز دارید که روی رایانه شما نصب شده باشد.
تفاوت بین وب جهانی و اینترنت
برخی از افراد از اصطلاحات “اینترنت” و “وب جهانی” به جای یکدیگر استفاده می کنند. تصور آنها این است که آنها یک چیز هستند، اما اینطور نیست. چرا که اینترنت با WWW کاملا متفاوت است.
زیرا یک شبکه جهانی از دستگاههایی مانند رایانه، لپتاپ، تبلت و غیره است. و کاربران را قادر میسازد برای سایر کاربران ایمیل ارسال کنند و با آنها به صورت آنلاین چت کنند. به عنوان مثال، وقتی ایمیلی ارسال می کنید یا با شخصی به صورت آنلاین چت می کنید، از اینترنت استفاده می کنید.
اما، هنگامی که وب سایتی مانند google.com یا seotolu.com را برای کسب اطلاعات باز کرده اید، از شبکه جهانی وب استفاده می کنید. شبکه ای از سرورها از طریق اینترنت شما با استفاده از یک مرورگر از رایانه خود یک صفحه وب درخواست می کنید و سرور آن صفحه را به مرورگر شما ارائه می دهد. به رایانه ی شما client گفته می شود که یک برنامه (مرورگر وب) را اجرا می کند و از رایانه دیگر (سرور) اطلاعات مورد نیاز خود را می خواهد.
تاریخچه شبکه جهانی وب
شبکه جهانی وب توسط یک دانشمند بریتانیایی به نام تیم برنرز لی در سال 1989 اختراع شد. او در آن زمان در CERN کار می کرد. در واقع برای اشتراک گذاری خودکار اطلاعات بین دانشمندان در سراسر جهان شبکه ی جهانی وب توسط برنز ایجاد گردید تا آنها بتوانند به راحتی داده ها و نتایج آزمایشات و مطالعات خود را با یکدیگر به اشتراک بگذارند.
سرن، همان جایی که تیم برنرز در آن کار میکرد، جامعه ای متشکل از 1700 دانشمند از بیش از 100 کشور جهان است. این دانشمندان مدتی را در سایت سرن می گذرانند و بقیه زمان را در دانشگاه ها و آزمایشگاه های ملی خود در کشور خود کار می کنند، بنابراین نیاز به ابزارهای ارتباطی قابل اعتماد برای تبادل اطلاعات وجود داشت.
اینترنت و هایپرتکست ها در آن زمان در دسترس بود، اما هیچ کس فکر نمی کرد چگونه از اینترنت برای لینک دادن یا اشتراک گذاری یک فایل به دیگران استفاده کند. تیم برنز روی سه فناوری اصلی تمرکز کرد که میتوانند باعث درک رایانهها از یکدیگر شوند، HTML، URL و HTTP. بنابراین، هدف از اختراع WWW ترکیب فناوریهای رایانهای ، شبکههای داده و هایپرتکست در یک سیستم اطلاعات جهانی کاربرپسند و مؤثر بود.
داستان از کجا شروع شد!؟
در مارس 1989، تیم برنرزلی ابتکار عمل را برای اختراع WWW به دست گرفت و اولین پیشنهاد برای وب جهانی را نوشت. بعداً در می 1990 پروپوزال دیگری نوشت و پس از چند ماه در نوامبر 1990 به همراه رابرت کالیو به عنوان پروپوزال مدیریت رسمیت یافت.
این پیشنهاد مفاهیم کلیدی و اصطلاحات تعریف شده مرتبط با وب را تشریح کرده بود. در این سند، توضیحی درباره “پروژه ابرمتن” به نام وب جهانی وجود داشت که در آن وب اسناد هایپرتکست توسط مرورگرها قابل مشاهده بود. پیشنهاد او شامل سه فناوری اصلی (HTML، URL و HTTP) بود.
در سال 1990، تیم برنرز لی توانست اولین وب سرور و مرورگر را در سرن اجرا کند تا ایده های خود را نشان دهد. او از یک کامپیوتر NeXT برای توسعه کد سرور وب خود استفاده کرد و یادداشتی را روی رایانه گذاشت ” دستگاه سرور است. آن را خاموش نکنید!” به طوری که به طور تصادفی توسط کسی خاموش نشده است.
در سال 1991، تیم اولین وب سایت و وب سرور جهان را ایجاد کرد. آدرس آن info.cern.ch بود و در CERN در رایانه NeXT در حال اجرا بود. علاوه بر این، اولین آدرس صفحه وب:
http://info.cern.ch/hypertext/WWW/TheProject.html بود. این صفحه دارای لینکهایی به اطلاعات مربوط به پروژه WWW و همچنین در مورد سرورهای وب، توضیحات هایپرتکست و اطلاعاتی برای ایجاد وب سرور بود.
مرحله رشد وب…!
پلت فرم کامپیوتر NeXT توسط چند کاربر قابل دسترسی بود. بعداً، توسعه مرورگر ‘line-mode’ که میتوانست روی هر سیستمی اجرا شود، آغاز شد. در سال 1991، Berners-Lee نرم افزار WWW خود را با مرورگر ‘line-mode’، نرم افزار وب سرور و کتابخانه ای برای توسعه دهندگان معرفی کرد.
در مارس 1991، در دسترس همکارانی بود که از رایانه های سرن استفاده می کردند. او پس از چند ماه در آگوست 1991 نرم افزار WWW را در گروه های خبری اینترنتی معرفی کرد و اینگونه در سراسر جهان به این پروژه علاقه مندانی پیدا شد. رابط گرافیکی برای اینترنت، اولین بار در 6 آگوست 1991 توسط تیم برنرز لی به عموم معرفی شد. و در 23 آگوست 1991 در دسترس همگان بود.
جهانی شدن
اولین وب سرور در دسامبر 1991 در ایالات متحده آنلاین شد. در این زمان فقط دو نوع مرورگر وجود داشت. نسخه توسعه اصلی که فقط در دستگاههای NeXT و مرورگر ‘line-mode’ موجود بود که نصب و اجرای آن بر روی هر پلتفرمی آسان بود، کاربرپسندتر بود اما قدرت محدودی داشت.
برای بهبود بیشتر، برنرز لی از سایر توسعه دهندگان از طریق اینترنت خواست تا در توسعه آن سهیم باشند. بسیاری از توسعه دهندگان مرورگرهایی را برای سیستم X-Window نوشتند. اولین وب سرور، خارج از اروپا، در دانشگاه استاندارد ایالات متحده در سال 1991 معرفی شد. در همان سال، تنها ده سرور وب شناخته شده در سراسر جهان وجود داشت.
بعداً در آغاز سال 1993، مرکز ملی برنامه های کاربردی ابر رایانه (NCSA) اولین نسخه مرورگر موزائیک خود را معرفی کرد. در محیط X Window System اجرا شد. بعداً NCSA نسخه هایی را برای محیط های PC و Macintosh منتشر کرد. با معرفی مرورگرهای کاربر پسند در رایانه ها، WWW به شدت در سراسر جهان گسترش یافت.
در نهایت، کمیسیون اروپا اولین پروژه وب خود را در همان سال با CERN به عنوان یکی از شرکای خود تصویب کرد. در آوریل 1993، سرن کد منبع WWW را بدون حق امتیاز در دسترس قرار داد و در نتیجه آن را به نرم افزار رایگان تبدیل کرد.
اصطلاح بدون حق امتیاز به این معنی است که شخص حق دارد از مطالب حق چاپ یا مالکیت معنوی بدون پرداخت حق امتیاز یا هزینه مجوز استفاده کند. بنابراین، CERN به مردم اجازه داد تا از کد و پروتکل وب به صورت رایگان استفاده کنند.
فنآوریهایی که برای ساخت WWW توسعه یافتند، به یک منبع باز تبدیل شدند تا مردم بتوانند به صورت رایگان از آنها استفاده کنند. در نهایت، مردم شروع به ایجاد وب سایت برای مشاغل آنلاین، برای ارائه اطلاعات و سایر اهداف مشابه کردند.
در پایان سال 1993 بیش از 500 وب سرور وجود داشت و WWW یک درصد از کل ترافیک اینترنت را در اختیار دارد. در ماه مه 1994، اولین کنفرانس بینالمللی وب جهانی در سرن برگزار شد و حدود 400 کاربر و توسعهدهنده در آن شرکت کردند و عموماً به عنوان “Woodstock of the Web” شناخته میشوند. در همان سال، شرکت های مخابراتی شروع به ارائه دسترسی به اینترنت کردند و مردم به WWW در خانه های خود دسترسی داشتند.
در همان سال یک کنفرانس دیگر در آمریکا برگزار شد که بیش از 1000 نفر در آن شرکت کردند. توسط NCSA و کمیته کنفرانس بین المللی (IW3C2) که به تازگی تشکیل شده بود، سازماندهی شد. در پایان این سال (1994)، شبکه جهانی وب حدود 10000 سرور و 10 میلیون کاربر داشت. این فناوری به طور مداوم برای برآوردن نیازها و امنیت رو به رشد بهبود مییابد و تصمیم گرفته شد ابزارهای تجارت الکترونیک به زودی اضافه شوند.
استانداردهای متن باز
هدف اصلی این بود که وب به جای یک سیستم اختصاصی، استانداردی باز برای همه باشد. بر این اساس، سرن پیشنهادی را تحت برنامه ESPRIT “WebCore” به کمیسیون اتحادیه اروپا ارسال کرد.
هدف این پروژه تشکیل یک کنسرسیوم بین المللی با همکاری موسسه فناوری ماساچوست (MIT)، ایالات متحده بود. در سال 1994، برنرز لی CERN را ترک کرد و به MIT پیوست و کنسرسیوم بین المللی وب جهانی (W3C) را تأسیس کرد و یک شریک اروپایی جدید برای W3C مورد نیاز بود.
کمیسیون اروپا به مؤسسه ملی فرانسه برای تحقیقات در علوم رایانه و کنترل (INRIA) مراجعه کرد تا نقش CERN را جایگزین کند. در نهایت در آوریل 1995، INRIA اولین میزبان اروپایی W3C و در سال 1996 دانشگاه Keio ژاپن میزبان دیگری در آسیا شد.
در سال 2003، ERCIM (کنسرسیوم تحقیقاتی اروپایی در انفورماتیک و ریاضیات) جایگزین INRIA برای نقش میزبان اروپایی W3C شد. دانشگاه بی هانگ به عنوان چهارمین میزبان توسط W3C در سال 2013 اعلام شد. در سپتامبر 2018، بیش از 400 سازمان در سراسر جهان عضو بودند.
وب از زمان پیدایش خود تغییرات زیادی کرده است و هنوز هم در حال تغییر است. موتورهای جستجو در خواندن، درک و پردازش اطلاعات پیشرفته تر شده اند. آنها به راحتی می توانند اطلاعات درخواستی کاربران را پیدا کنند و حتی می توانند اطلاعات مرتبط دیگری که ممکن است مورد علاقه کاربران باشد را ارائه دهند.
وب جهانی چگونه کار می کند؟
اکنون فهمیدیم که WWW مجموعهای از وبسایتهای متصل به اینترنت است تا افراد بتوانند اطلاعات را جستجو و به اشتراک بگذارند. حالا بیایید ببینیم که چگونه کار می کند!
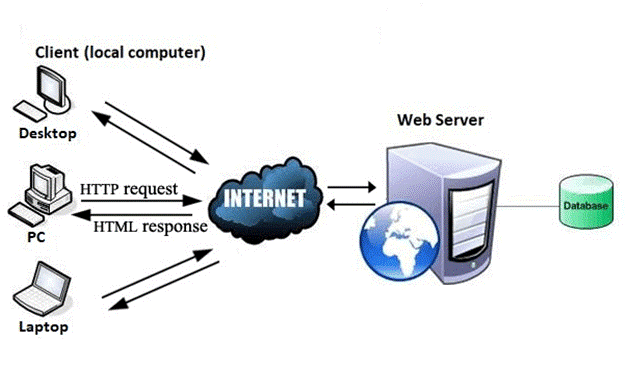
وب طبق فرمت اصلی سرویس گیرنده-سرور اینترنت همانطور که در تصویر زیر نشان داده شده است کار می کند.
سرورها صفحات وب یا اطلاعات را در صورت درخواست کاربران، ذخیره و به رایانه های کاربر در شبکه منتقل می کنند. وب سرور یک برنامه نرم افزاری است که صفحات وب درخواستی کاربران وب را با استفاده از مرورگر ارائه می دهد.
کامپیوتر کاربری که اسناد را از سرور درخواست می کند به عنوان کلاینت شناخته می شود. مرورگری که بر روی رایانه کاربر نصب شده است، به کاربران امکان می دهد اسناد بازیابی شده را مشاهده کنند.
تمام وب سایت ها در سرورهای وب ذخیره می شوند. همانطور که شخصی در یک خانه اجاره ای زندگی می کند، یک وب سایت فضایی را در سرور اشغال می کند و در آن ذخیره می شود. سرور هر زمان که کاربر صفحات وب خود را درخواست می کند وب سایت را میزبانی می کند و مالک وب سایت باید هزینه میزبانی را برای آن بپردازد.
لحظه ای که مرورگر را باز می کنید و یک URL را در نوار آدرس تایپ می کنید یا چیزی را در گوگل جستجو می کنید، WWW شروع به کار می کند. سه فناوری اصلی در انتقال اطلاعات (صفحات وب) از سرورها به مشتریان (کامپیوترهای کاربران) وجود دارد. این فناوری ها عبارتند از زبان نشانه گذاری Hypertext (HTML)، پروتکل انتقال Hypertext (HTTP) و مرورگرهای وب.
زبان نشانه گذاری Hypertext (HTML)
HTML یک زبان نشانه گذاری استاندارد است که برای ایجاد صفحات وب استفاده می شود. ساختار صفحات وب را از طریق عناصر یا برچسب های HTML توصیف می کند. این برچسب ها برای سازماندهی قطعات محتوا مانند “عنوان”، “بند”، “جدول”، “تصویر” و موارد دیگر استفاده می شود.
وقتی یک صفحه وب را باز می کنید، تگ های HTML را نمی بینید زیرا مرورگرها tag ها را نمایش نمی دهند و از آنها فقط برای ارائه محتوای یک صفحه وب استفاده می کنند. به عبارت ساده، HTML برای نمایش متن، تصاویر و سایر منابع از طریق مرورگر وب استفاده می شود.
مرورگر اینترنت
مرورگر وب که معمولاً به عنوان مرورگر شناخته می شود، برنامه ای است که متن، داده، عکس، فیلم، انیمیشن و غیره را نمایش می دهد. این یک رابط نرم افزاری ارائه می دهد که به شما امکان می دهد روی منابع لینکی در شبکه جهانی وب کلیک کنید. وقتی روی نماد مرورگر نصب شده روی رایانه خود دوبار کلیک می کنید تا آن را راه اندازی کنید، به شبکه جهانی وب متصل می شوید و می توانید در گوگل جستجو کنید یا یک URL را در نوار آدرس تایپ کنید.
در ابتدا مرورگرها به دلیل پتانسیل محدودی که داشتند فقط برای مرور استفاده می شدند. ولی امروزه آنها پیشرفته تر هستند. درکنار مرور و سرچ، می توانید از آنها برای ارسال ایمیل، انتقال فایل های چند رسانه ای، استفاده از سایت های رسانه های اجتماعی و شرکت در گروه های گفتگوی آنلاین و موارد دیگر استفاده کنید. برخی از مرورگرهای رایج عبارتند از Google Chrome، Mozilla Firefox، Internet Explorer، Safari ، Opera،Brave و …
پروتکل انتقال Hypertext (HTTP)
پروتکل انتقال متن بیش از حد یا Hyper Text Transfer Protocol که به اختصار (HTTP) گفته میشود یک پروتکل لایه کاربردی است که WWW را قادر میسازد تا روان و مؤثر کار کند. کارکرد آن بر اساس مدل مشتری-سرور است.
مشتری یک مرورگر وب است که با وب سروری که وب سایت را میزبانی می کند ارتباط برقرار می کند. این پروتکل نحوه قالب بندی و ارسال پیام ها و اقداماتی که وب سرور و مرورگر باید در پاسخ به دستورات مختلف انجام دهند را مشخص می کند. هنگامی که یک URL را در مرورگر وارد می کنید، یک دستور HTTP به سرور وب ارسال می شود و صفحه وب درخواستی را ارسال می کند.
وقتی وب سایتی را با استفاده از مرورگر باز می کنیم، اساس کار به این صورت است که یک اتصال به وب سرور باز می شود و مرورگر از طریق HTTP با سرور ارتباط برقرار می کند و درخواست ارسال می کند. HTTP از طریق TCP/IP برای ارتباط با سرور منتقل می شود. سرور درخواست مرورگر را پردازش می کند و پاسخی را ارسال می کند و سپس اتصال بسته می شود. بنابراین، مرورگر محتوا را از سرور برای کاربر بازیابی می کند.
تفاوت بین موتور جستجو و پورتال
تعریف موتور جستجو
موتور جستجو (Search Engine) برنامهای است که به کاربران امکان میدهد اطلاعات یا محتوا را در شبکه جهانی وب مشاهده کنند. و به بازیابی اطلاعات مورد نظر در حداقل زمان کمک می کند. موتور جستجو به شما امکان می دهد کلمات یا عبارات کلیدی خاصی را وارد کنید و لیستی از موارد مطابق با آن کلمات و عبارات کلیدی را بازیابی کنید. بنابراین، اطلاعات را فوراً ارائه نمی کند. فقط صفحاتی را مورد بررسی قرار میدهد که به کلمات کلیدی یا سایر عبارات جستجو مرتبط هستند. برخی از موتورهای جستجوی محبوب گوگل، بینگ و یاهو هستند!
پورتال
پورتال (Portal) یک مکان خصوصی در اینترنت است که به عنوان نقطه دسترسی به اطلاعات موجود در شبکه جهانی وب عمل می کند. یک پورتال از طریق یک URL منحصر به فرد، نام کاربری و رمز عبور منحصر به فرد قابل دسترسی است، یعنی به غیر از URL، برای مشاهده محتوای یک پورتال به ورود شخصی نیاز است. برخی از پرتال های محبوب facebook.com، gmail.com و twitter.com هستند.
الگوریتم های گوگل

در آغاز دهه ی 90، موتورهای جستجو به اندازهی امروز کارآمد نبودند. در گذشته گوگل بیشتر بر روی تطبیق کلمات کلیدی و بک لینک ها تمرکز داشت. به همین دلیل، برای وب سایت هایی که کیفیت پایین داشتند نیز بسیار آسان بود که با کلمات کلیدی مد نظر خود با ایجاد تعداد زیادی بک لینک، رتبهی بالاتری در گوگل کسب کنند.
برای حل این مشکل، گوگل الگوریتمی را برای فیلتر کردن نتایج معرفی کرد تا از این طریق بتواند وب را پاک کند. از آن پس، گوگل به طور مداوم الگوریتم خود را برای حفظ و بهبود کارایی موتور جستجوی خود به روز می کند.
برخی از الگوریتم های اصلی گوگل که به غربال سایتها، فیلتر کردن آنها و پاکسازی مؤثر وب کمک شایانی کرد، در زیر اشاره خواهیم کرد:
الگوریتم های سال 2019
در اکتبر 2019، با کمک این به روز رسانی، گوگل، الگوریتم و سختافزار خود را برای درک مدل پردازش زبان طبیعی BERT (NLP) ارتقا داد. BERT به گوگل اجازه می دهد تا جستجوهای زبانی را بهتر تفسیر و درک کند و در نتیجه، نتایج جستجو را بهبود بخشد.
به روز رسانی تنوع سایت
در ژوئن سال 2019 برای بهبود شرایط و جایگاه سایتهایی که بیش از دو فهرست ارگانیک داشتند، معرفی شد.
الگوریتم سال 2018
الگوریتم مربوط به سرعت سایت در موبایل
در سال 2018 گوگل به روز رسانی سرعت صفحه موبایل را معرفی کرد تا سرعت صفحه را به عنوان یک فاکتور رتبه بندی برای نتایج تلفن همراه لحاظ کند. گوگل گفت که این فقط بر روی سایت های موبایلی که سرعت لود آنها کند است تاثیر می گذارد.
به روز رسانی 2017
Fred
در 8 مارس 2017 در پاسخ به محتواهای بی کیفیت، وابسته به تبلیغات معرفی شد. این الگوریتم سایت ها یا وبلاگ هایی را مورد هدف قرار داشت که محتوای با کیفیت پایین ارائه می دهند و عمدتاً به منظور ایجاد درآمد از طریق تبلیغات ساخته شده اند.
به روز رسانی های سال 2016
پنگوئن 4.0 در 23 سپتامبر 2016 توسط گوگل معرفی شد، این الگورتیم با تغییرات جزئی بخشی از الگوریتم اصلی قرار گرفت، در به موقع به روز می شود و به جای اینکه کل دامنه را تحت تاثیر قرار دهد، مختص صفحه می باشد.
الگوریتم Boost Friendly Mobile
در 12 می 2016 راه اندازی شد تا به سایت های سازگار با موبایل در جستجوهایی که توسط موبایل صورت میگیرند کمک کند و در نتایج بالاتر نشان دهد.
الگورتیم های سال 2015
الگوریتم پاندا 4.2
در 17 ژوئن سال 2015، گوگل الگوریتم پاندا (Panda 4.2)را عرضه کرد. هیچ تاثیر فوری بر روی رتبه بندی ندارد. به گفته گوگل، بعد از این الگورتیم 23 درصد از جستجوهایی که به زبان انگلیسی انجام میشده را تحت تأثیر قرار داده است.
الگوریتم مناسب برای موبایل (Mobilegeddon)
این الگورتیم در 21 آوریل 2015 منتشر شد. این الگوریتم، ویژگی سازگاری با تلفن همراه را به یک فاکتور رتبه بندی مهم برای جستجوهای تلفن همراه تبدیل کرد. وظیفه آن افزایش رتبه صفحاتی بود که سازگاری خوبی با موبایل داشتند تا بتوان محتوای با کیفیت و مرتبط را در اختیار کاربران موبایل قرار داد.
الگوریتم های سال 2014
الگورتیم پنگوئن 3.0
این الگوریتم در 17 اکتبر 2014 توسط گوگل معرفی شد. این فقط یک به روز رسانی بود و به وب سایت هایی کمک کرد تا رتبه خود را افزایش دهند که در به روز رسانی قبلی، یعنی Penguin 2.1 از رتبه خارج شده بودند.
الگوریتم پاندا 4.1
این بیست و هفتمین نسخه پاندا بود که توسط گوگل در 23 سپتامبر 2014 منتشر شد. گوگل گفت که به موتور جستجو کمک می کند تا محتوای ضعیف و بی کیفیت را شناسایی کند تا وب سایت های کوچک یا متوسط با محتوای با کیفیت بالا، رتبهی بهتری داشته باشند.
الگوریتم کبوتر
در ژوئیه 2014 برای مشاغل محلی راه اندازی شد. گوگل گفت که روابط نزدیکتری بین الگوریتمهای محلی و اصلی ایجاد میکند تا کاربران بتوانند اطلاعات مفید و دقیق را در نتایج جستجوی محلی خود بیابند.
الگوریتم پاندا 4.0
این آپدیت پاندا در 19 می 2014 برای کمک به وب سایت ها و مشاغل کوچک با منابع محدود معرفی شد. این
در واقع یک به روز رسانی داده یا تغییر در الگوریتم پاندا بود.
به روز رسانی های سال 2013
الگوریتم مرغ مگس خوار 1.0
در 20 آگوست 2013 توسط گوگل برای درک بهتر ظاهر در حال تغییر وب معرفی شد. با استفاده از این الگوریتم به جای اینکه فقط یک کلمه کلیدی خاص را تشخیص دهد، قادر به درک هدف عبارات جستجوی طولانی بود. این به گوگل کمک کرد تا عبارات جستجوی دم بلند (کلمات کلیدی بلند) را بشناسد و به طور دقیق پاسخ های چنین کلمات کلیدی دم بلندی را رتبه بندی کند. یعنی به کاربران این امکان را میدهد تا سوال بپرسند و پاسخ های مناسب را دریافت کنند.
به روز رسانی های سال 2012
الگوریتم پنگوئن
در 24 آوریل 2012 این الگوریتم سایت هایی را مورد هدف خود قرار داد که با خرید لینک ها یا استفاده از برخی شبکه های لینک دیگر که به منظور افزایش رتبه طراحی شده اند، معرفی شد به عبارتی این سایت ها اسپم بودند. گوگل نیز از طریق ابزارهای وب مستر هشدارهایی به صاحبان سایت ها ارسال کرد و آنها را به دلیل رعایت نکردن دستورالعمل های خود جریمه کرد.
آپدیت های سال 2011
الگوریتم پاندا/ Farme
این الگوریتم برای اولین بار در 24 فوریه 2011 عرضه شد. کار این الگوریتم اختصاص امتیاز و نمره به صفحات وب بر اساس کیفیت محتوا بود و از طرفی سایت هایی را که محتوای بی کیفیت داشتند را نیز جریمه میکرد و رتبهی آن سایت را کاهش میداد. وظیفه این الگوریتم شناسایی و حذف رتبهی سایتهای مزرعه محتوا بود که محتوای کم یا سایتهایی با تبلیغات بالا به نسبت محتوا ارائه میکردند.
آپدیت های سال 2010
الگوریتم کافئین
در ژوئن 2010، گوگل، الگوریتم کافئین خود را برای معرفی یک سیستم ایندکسینگ وب سایت جدید ارائه کرد. این به گوگل کمک کرد تا سرعت موتور جستجو را بهبود بخشد و خزیدن و ایندکس یکپارچه را انجام دهد که منجر به ایندکس 50% جدیدتر شد.
به روز رسانی های 2009
الگوریتم کافئین (پیش نمایش)
در آگوست 2009، گوگل کافئین (پیشنمایش) را منتشر کرد، تغییرات زیرساختی که برای بهبود و ادغام ایندکس، خزیدن، و وسعت ایندکس موتور جستجوی خود.
وینس (Vince)
وینس در فوریهی سال 2009 معرفی شد. این به روزرسانی به عنوان یک تغییر بزرگ بحساب میآمد زیرا که به نفع برندهای بزرگ بود، اما گوگل؟
سپس مت کاتس تایید کرد که این یک تغییر جزئی است که بر سیگنال های رتبه بندی مانند اتوریتی و اعتماد سایت متمرکز شده است.
آپدیت های سال 2007
بافی (Buffy)
در ژوئن 2007 معرفی شد. این به روز رسانی به افتخار ونسا فاکس گوگل نامگذاری شد. مت کاتز گفت که این فقط برخی تغییرات جزئی همانند تکمیل نتایج جستجو با اخبار، تصاویر و ویدئوها و غیره است.
آپدیت سال 2005
بابا بزرگ (Bigdaddy)
در دسامبر 2005 عرضه شد. این به روزرسانی در واقع یک تغییر زیرساخت بود که نکات فنی جدیدی را در رابطه با متعارف سازی URL، تغییر مسیرها و غیره به ارمغان آورد. این آپدیت به گوگل کمک کرد تا برای پیشرفت های آینده آماده شود.
به روز رسانی های 2004
براندی (Brandy)
این بهروزرسانی در فوریه 2004 راهاندازی شد. این آپدیت ایندکس گوگل را گسترش داد و LSI (Latent Semantic Indexing ) را در خود جای داد که به گوگل امکان میدهد مترادفها را بهتر درک کند.
آستین (Austin)
در 23 ژانویهی سال 2004 معرفی شد. این به روز رسانی در واقع پیشرفت در الگوریتم فلوریدا بود. این تاکتیکهای اسپم روی صفحه مانند متنهای پنهان و متا تگهایی را که بیش از حد پر میشدند را هدف قرار داد.
به روز رسانی های 2003
فلوریدا
این الگوریتم در 16 نوامبر 2003 توسط گوگل معرفی شد. با آمدن الگوریتم فلوریدا تغییرات قابل توجهی در الگوریتم گوگل ایجاد شد و پس از آن دیگر صاحبان وب سایت ها نمیتوانستد با استفاده از پر کردن کلمات کلیدی نتایج موتورهای جستجو دستکاری کنند.
فریتز (Fritz)
در جولای 2013 عرضه شد. با استفاده از این الگوریتم، گوگل روش خود را برای به روز رسانی ایندکس تغییر داد. با آمدن این الگوریتم به جای اینکه هر ماه ایندکس انجام شود، به صورت روزانه ایندکس صورت گرفت که این خود یک تغییر بسیار بزرگی بود.





